WHAT HAPPENS WHEN YOU TYPE 'www.google.com' IN THE BROWSER
Behind the scene when you enter "www.google.com"

I have always had A question in mind whenever I use a browser. How does all of this work it seems like magic from just typing a URL in the browser, to a full webpage at your request. My aim with this blog post is to explain how the internet and your browser work to deliver your web page.
Once you type 'www.google.com' and hit enter
The browser checks its cache (Where it stores data for easy lookup) for the IP Address of "www.google.com", IP address is how computers identify themselves on the internet.
If you haven't gone to "www.google.com" recently or have just cleared your browser cache, Then the browser constructs a DNS (Domain Name System) query to the resolving name server that sits between the client (browser) and authoritative name servers.
The DNS resolving name server queries the root name server which returns a list of Top Level Domain Name (TLD) Servers for .com.
When the resolving name server gets the list containing TLD names, it asks the famous question "Who is Google" to the nearest TLD server. The TLD name server returns a list of authoritative name servers associated with "Google".
The resolving name server would put a final request to the authoritative name server which returns the IP address.
The resolving name server returns the IP address to the client which put a final request to the server hosting the web page we see when we type "google.com"
A lot of this happens behind the scene and is designed to take as less time as possible, usually done by the ISP (Internet Service Provider) which is the resolving name server. IP addresses are cached at any stage by either the client or the resolving name server to speed up DNS lookup.
The client has to figure out how to communicate with the server after getting the IP address of the server. The conceptual agreement between the client and server or all devices on the internet that covers data transport is the TCP/IP model.
TCP/IP Model
Transmission Control Protocol and Internet Protocol describe how data on the internet is addressed, packaged, sent and received. In other to do this a conceptual divide is used to group similar functions into layers known as TCP/IP model. The TCP/IP model inherits from the OSI model, don't worry about the OSI model just yet but keep in mind all model on the internet inherits from the OSI model.
Network Access Layer
This layer is also known as the link layer, it is the lowest layer of the TCP/IP model, It is the only layer that deals with the hardware directly. It sends data between hosts on a network. If you turn on your phone hotspot and another device connects with their wifi you have successfully created a LAN (local area network).
The network access layer deals with transmitting data from the higher layer to the physical layer which interacts with the transmitting medium in the form of an electrical signal in the hardware.
Internet Layer
Protocols in this layer describe how data is sent and received over the internet. The process includes packaging data into packets, transmitting packets, and addressing and receiving packets from the network access layer of TCP/IP.
Transport Layer
This layer encapsulates TCP (Transmission Control Protocol) and UDP (User Datagram Protocol) both protocols have their trades off when it comes to transporting packets of data over the internet. TCP is used where reliability is a priority because whenever TCP sends a packet, it waits to receive confirmation from the client or server before resending the packet after a predefined time.
UDP is used where speed is a priority and latency of data cannot be tolerated like in video stream or game stream. UDP works by sending packets of data to the client without receiving feedback from the client or server receiving the packets.
TCP is a connection-oriented transport layer protocol and UDP is a connectionless transport layer protocol.
Application Layer
This encompasses protocols the web browser interacts with when you type "www.google.com" and when you hit enter. These protocols include and are not limited to HTTP (HyperText Transfer Protocol), HTTPS (HyperText Transfer Protocol Secure), Telnet (For remote login to servers), and SSH (Secure Shell).
So at this point, we know how the browser knows where to find the Google server that hosts the webpage that we all love and also know how the server and client can communicate through what seems like thin air as I like to think.
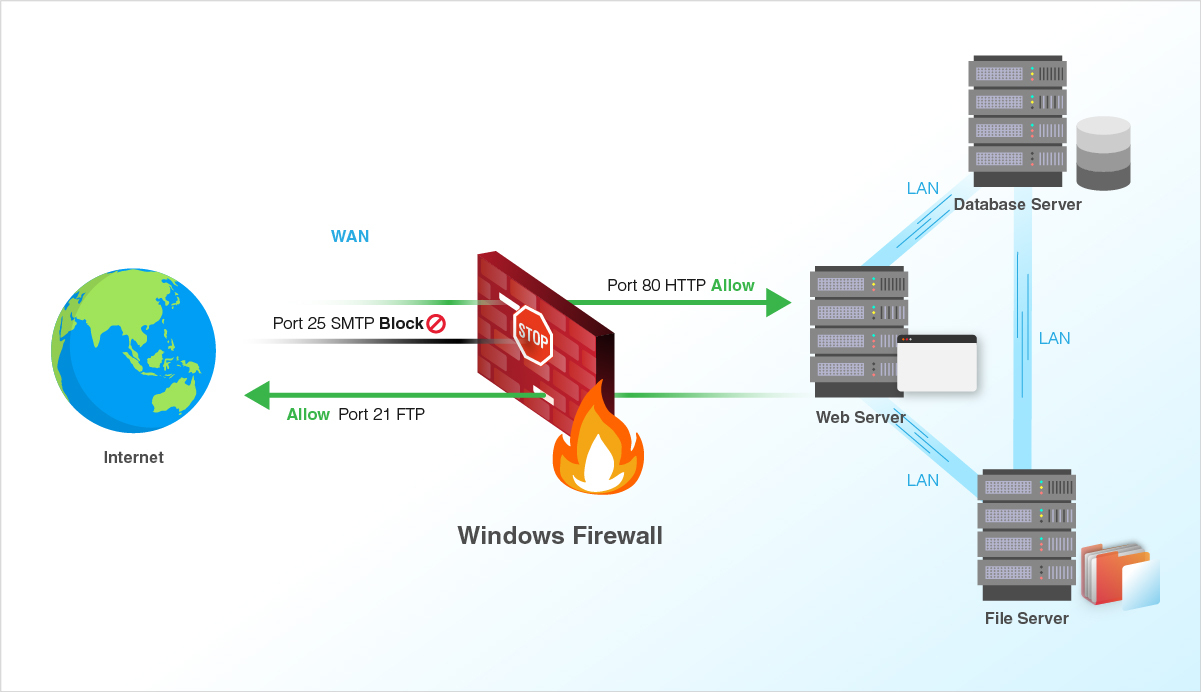
Firewall
Firewalls expose ports on a computer to be accessible to another computer on the network or outside the network (internet) and also block ports that are not supposed to be public facing from being accessed by other computers on the network. You might be thinking why do we need a firewall, Without a firewall every file or personal document on your phone or computer would be accessible by others on the internet.
Now let's assume that we were able to get the IP address of the server of "www.google.com" If the port used to serve pages on the internet which is usually port 80 for HTTP and 443 for HTTPS isn't exposed to the internet and listening for request we wouldn't be able to establish the connection to the server via TCP hence no respond.
HTTPS/SSL
Imagine screaming the password of your phone or bank account in the market, that is what happens when a website doesn't take into account security in their design. Lucky for us Google does, so I would explain what happens on the security aspect of things in a few paragraphs stay tuned.
In other to encrypt the communication SSL(Secure Socket Layer) is employed which use asymmetric encryption (two different key are used) and symmetric encryption (one same key is used) to authenticate and encrypt the server
In SSL authentication is done with asymmetric encryption while data transfer following that is done with symmetric encryption. First, the server has a private key that can only be stored privately in the web server and a public that can be sent to anyone in need of it. The public key is used to encrypt messages that can only be decrypted by the private that is in the possession of the web server.
SSL HANDSHAKE
The client sends an initial message to the server that includes the SSL version that would be used to encrypt during the data transfer.
The server responds with its public key, an SSL certificate that the client would verify with the issuer If it is now the server there authenticating the server identity (avoiding man-in-the-middle attack), choosing its choosing cipher suits and a random string.
The client generates another random string known as the premaster encrypts it with the public key and sends it to the server.
The server decrypts the random string using its private key.
Using the random strings from both server and client they both generate a Session ID that is the same.
They both have a Session ID that has not been transmitted on the network. The client and server use this negotiated Session ID to encrypt subsequent data transfer
At this point, we are now able to communicate with the server securely. There is still another unanswered question how does Google handle the load of traffic that it receives and doesn't seems to ever have downtimes?
Load Balancing

The image above shows a load balancer distributing traffic to different servers managed by Google.
A load balancer is a hardware or software that acts as a reverse proxy and distributes traffic to multiple servers thereby increasing reliability and redundancy.
SSL Termination
The load balancer is mostly used for SSL TERMINATION where HTTPS connection is terminated at the load balancer then the load balancer makes a connection to the server for the client to return the responses of the server to the client essentially creating a secured gateway. This reduces the tedious work of managing private and public keys in multiple servers.
Google server is now able to handle our traffic reliably, how is it able to serve and respond to us with the website we want?
WEB SERVER
A web server contains minimum of a static files and an HTTP server that parses URLs and sends you content related to the URL you passed to it. You have noticed how the content of the pages that are returned when to depends on a lot of factors, hence would the content of the page must change with time.

There are two types of web servers.
A Static Webserver or stack is called static because it sends the hoisted file on it without any changes to your browser with an HTTP server
A Dynamic Webserver is a superset of the static web server it contains the static web server and extra software which are an Application Server and a Database Server, It update hoisted template file with content from the database.
Application Server
An application server is software that lives on the server side and usually acts as a middleware between the HTTP server and a database Server, It is responsible for finding the requested content from the database and hydrating the template returning a full webpage or an error page that would be sent to you by the HTTP server.
Database Server
A Database is a server that is located behind a network and it is dedicated to data storage and retrieval. The database server holds the DBMS (database management system) and the database and upon request finds the record related to what the client wants and returns it through the application server.
The database server in a distributed network would include a master and slave or master and replica database server the master sync with its slave servers in real-time.
Conclusion
When you type "www.google.com" in the browser, The browser checks its cache memory If it can't find the IP address of the web server hosting Google. It queries the DNS resolver name server which returns the IP address if exists in the DNS record of an authoritative name server. The server uses TCP/IP to communicate with the server which returns the webpage.

